Guide to Data Classification: Sensitive vs Public
Automated data classification in RecordPoint lets you identify and protect sensitive information — including Personally Identifiable Information — easily and instantly.


Published:
July 12, 2022
Last updated:
January 21, 2025

• Data classification organizes information by sensitivity, business context, and compliance requirements. • Public, confidential, internal, and restricted levels guide risk-based data protection. • Automated tools enhance visibility, enforce controls, and scale governance processes. • Encryption, access permissions, and multi-factor authentication safeguard sensitive and confidential information. • Robust classification supports audit readiness and helps meet regulatory data privacy obligations.
Finding it hard to keep up with this fast-paced industry?
Subscribe to FILED Newsletter.
Your monthly round-up of the latest news and views at the intersection of data privacy, data security, and governance.
Subscribe Now
Data is at the heart of every modern organization. And regulators expect businesses to know where their customer data lives and to take action to protect it. At the same time, customers demand that their sensitive data remain protected. Failure to protect customer data may result in legal consequences and damage to an organization’s reputation.
Meeting these obligations becomes even harder when business data is spread over multiple structured and unstructured data sources, not to mention the constant threat of data breaches. As of 2024, the average cost of a data breach stood at a hefty $4.88M.
To meet these challenges, businesses need to first understand what data they have and classify it according to business needs and sensitivity.
What is data classification?
Data classification is the process of grouping information based on sensitivity, types, and business context. By classifying data, organizations can better manage sensitive data or confidential information and protect it from unauthorized access.
In this article, you’ll learn why it’s vital to classify your data, understand the four standard data classification levels, and how automation can make it easier to keep your company’s data safe and compliant.
What is the difference between data classification and data categorization?
Though the words are often used interchangeably, data classification and data categorization are two distinct processes related to the organization of data.
While the classification of data types is focused on grouping information according to sensitivity, data categorization is focused on making data easier to use by assigning labels or identifiers to each category, so that it can be distinguished from other types of data.
Both processes are essential to an organization's governance efforts, but this post will focus on data classification and its role in your organization’s security and compliance efforts.
.png)
Why classify your data?
Classifying your data is essential for several reasons. Of the many data classification benefits, it all starts with data clarity.
Data classification helps you understand:
- Exactly what kind of information you’re storing
- The value of information to your organization
- The criticality of information to your business process
- How the data could be used if lost or hacked
Having a clear understanding of the different types of data lets you make more informed decisions about the storage location and necessary access controls for your data.
Finally, it also makes life easier when dealing with compliance obligations, like financial regulations and audit requirements. Sensitive information like credit card details and Personal Identifiable Information (PII) must be handled differently to ensure the highest levels of security and compliance with privacy regulations.
Data classification definitions
When it comes to classifying data, every organization’s needs and requirements are unique. However, while each organization is different, there is some common ground.
Specific industries will have detailed standards and definitions for their data types. For example, in government and highly regulated industries such as the financial and healthcare sectors, there are often five levels of data: Top Secret, Secret, Confidential, Sensitive, and Unclassified.
Various forms of data may encompass information categorized as sensitive. Examples of sensitive data include credit card numbers, bank account details, driver’s license numbers, social security numbers, as well as birth dates and email addresses.
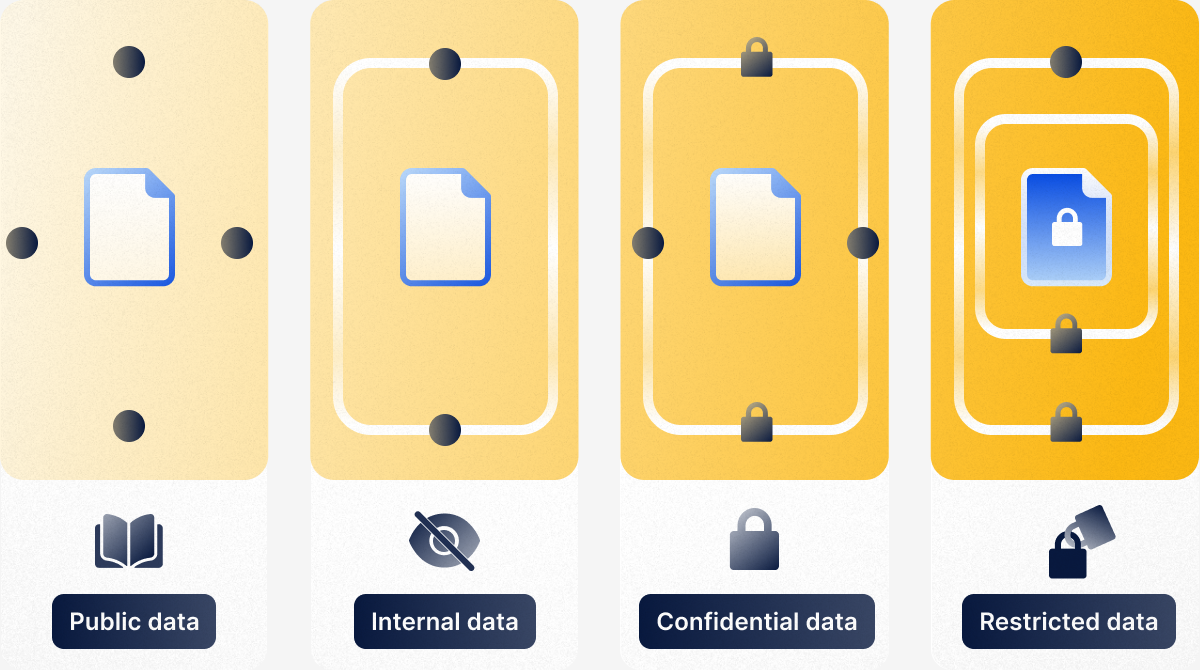
Let's explore some common methods for categorizing data at a higher level:
- Public data poses a minor risk if disclosed, as anyone can easily access it. For example, non-confidential industry reports, directories, and a company’s pricing models would all be classified as public information. This data is not considered sensitive.
- Confidential data must remain private and protected at all times. Leaking of this kind of data which may include Social Security numbers, medical records, bank account details, or employment contracts can cause serious financial, legal, or regulatory consequences.
- Internal data isn’t intended for public release, but it may be accessed under the Freedom of Information Act (FOIA) or similar legislative regimes. This should be assessed to gauge potential damage, though likely minimal. One example of confidential internal data would be a business’ organizational flow chart, which visually represents your company’s structure, roles, and relationships.
- Restricted data can have serious financial, legal, or regulatory consequences for your business if revealed. This classification requires additional controls and is likely subject to additional security standards. Protecting restricted data, which can include things like legal contracts, financial forecasts, IP, and data relating to mergers and acquisitions, must be taken seriously.
What is sensitive information?
Sensitive data refers to any private information that must be protected from loss, or information that could cause both reputational and financial damage to your organization if released. Sensitive data can include both physical and digital formats like documents, photographs, videos, or audio. Most businesses have sensitive personal information collected in their network and are required to follow compliance laws or face significant penalties.
If sensitive data is exposed or gets into the wrong hands, it can have severe consequences that can escalate into a security breach.
Sensitive Data Best Practices
Here are a few ways you can safeguard sensitive data:
- Implement strong access controls such as role-based access permissions
- Enforce multi-factor authentication (MFA) to add an extra layer of security
- Encrypt sensitive data both in transit and at rest by using Secure Sockets Layer (SSL) or Transport Layer Security (TLS) protocols
- Classify all documents
- Apply data masking (obfuscation) techniques to create fake versions of sensitive data
- Establish a data governance framework that includes both policies and procedures for managing and maintaining data quality
- Regularly update your records and delete outdated data to maintain data freshness
- Back up all data in the event of a security incident
- Conduct periodic reviews and audits of data processes to ensure ongoing data quality
- Ensure you’re up-to-date with compliance regulations
- Train and educate your team on data classification policies and best practices
We’ve also outlined a complete guide on data privacy and sensitive information you should implement within your organization.

Confidential vs. Sensitive information
Confidential information is data that is not accessible to everyone. It’s often private, but not always. Confidential information can be anything from a credit card number to patent applications.
In a business context, confidential information refers to any data, knowledge, or information pertaining to the functioning of your business that is not publicly disclosed or available in the public domain. Here are some examples of what might be classified as confidential information:
- Proprietary Information (e.g. software code, copyrights, trademarks, patents)
- Financial Information
- Medical Information
- Trade secrets
- Personal information
- Employee data
- Contracts and agreements

An overview of data privacy laws
Data privacy laws determine how a company may use, store, and share personal information. They are designed to protect against identity theft and fraud, and ensure confidentiality protection. They also control how businesses interact with customers by dictating methods of collecting information as well as how that data can be used.
Today, nearly 80% of the world’s population is protected by some form of a national data privacy law. Let's look at two prominent examples for a look at how such regulation may function. GDPR and HIPAA.
The General Data Protection Regulation (GDPR)
GDPR is a European Union data protection law that gives EU citizens more control over their personal data. It applies to any company that targets or processes the personal data of individuals in the EU, regardless of where the company is located. No matter where the companies are headquartered or operating, companies that process the personal data of EU citizens must comply with the framework.
Businesses subject to the GDPR must secure explicit consent from individuals before collecting, using, or sharing their personal data. They’re also required to provide individuals with clear and concise information about their rights under the GDPR and ensure that individuals can easily exercise their rights. Failure to comply can result in exorbitant fees. Meta, Facebook’s parent company, was hit with a record-breaking $1.3B fine in 2022 for violating EU GDPR data privacy laws.
HIPAA protects health information in the United States
The Health Insurance Portability and Accountability Act of 1996 (HIPAA), which applies to organizations in the United States, defines Personal Health Information (PHI) as individually identifiable health information. HIPAA was signed into law by President Bill Clinton on August 21, 1996 in an effort to promote the use of electronic transactions in the healthcare industry and to protect the confidentiality of healthcare information.
Protected health information includes demographic information, such as name, age, and sex; information about the individual’s health history, including mental health conditions; and the results of any tests or examinations performed on the individual.
The heavily regulated healthcare sector carries the highest cost for a data breach, standing at a whopping $10.93M, more than twice the cost of a standard data breach. HIPAA violations are broken down by tiers, with the maximum penalty carrying a fine upwards of $100,000 as of 2024. RecordPoint helps safeguard sensitive patient privacy and provides a continuous data inventory and categorization process in the highly regulated healthcare sector.
Auto-classification means more actionable insights
Organizations of all sizes are collecting more data than ever before. This influx could make it more difficult for your business to understand its data, and to make the right business decisions and maintain compliance. That’s where data classification tools like RecordPoint come in.
The RecordPoint solution
With RecordPoint, you can effortlessly create a data inventory, classify and categorize your data based on sensitivity and business objectives, and use built-in reporting features to maintain a clear picture of your organization’s privacy posture.
Discover Connectors
View our expanded range of available Connectors, including popular SaaS platforms, such as Salesforce, Workday, Zendesk, SAP, and many more.
Explore the platform
Get automated categorization
Understand the data you're working with, and how best to handle it to reduce risk with RecordPoint Data Categorization.
Learn More
Related Posts
See All