RecordPoint Platform Service Description
Table of Contents
Overview
The RecordPoint Platform provides organizations with a cloud-based information governance platform that is comprehensively operated and managed.
RecordPoint has an adaptable layer of intelligence that connects all your data and content across platforms, helping you achieve greater operational efficiency while keeping data compliant and reducing risk.
On-going assessment, proactive monitoring, and reporting of the service along with a continuous update process, ensures hassle-free compliance with your information governance requirements.
RecordPoint is available in multiple geographies to maintain customer data sovereignty.
High availability and continuous replication of data ensure service continuity should the primary data stores fail. High availability and replication within a data center region are included in the service.
We’re always searching for new ways to improve our products and services. Here are just a few of the ways we’re continually improving our technology, subject matter expertise, and commitment to ongoing innovation.
Global reach with multiple data centers
In addition to our existing U.S. data center, we’ve expanded our customers’ global reach with data centers in the United States, Canada, the UK, and Australia, with more additions planned.
Evergreen upgrades
RecordPoint is always evolving. We are relentless in our pursuit to provide the best experience so that you can manage your information with an ever-growing suite of features and functions.
Extensive Connector framework
We consistently release new connectors that help you extend advanced governance across multiple sources, including Microsoft Exchange Online, Dropbox, Teams, and others. You can also develop your own custom connectors. Our Connector framework allows for connection to hundreds of the business systems your business relies on. Whatever the system or use case, Connectors ensure your information is managed in an automated, compliant manner.
Your trusted partner
We understand security is paramount for our customers. In this trust portal you’ll find information about how RecordPoint keeps your information secure.
A better return on your investment
Our variety of plans and rate-based licensing model help make it more affordable for any organization to subscribe to and implement RecordPoint.
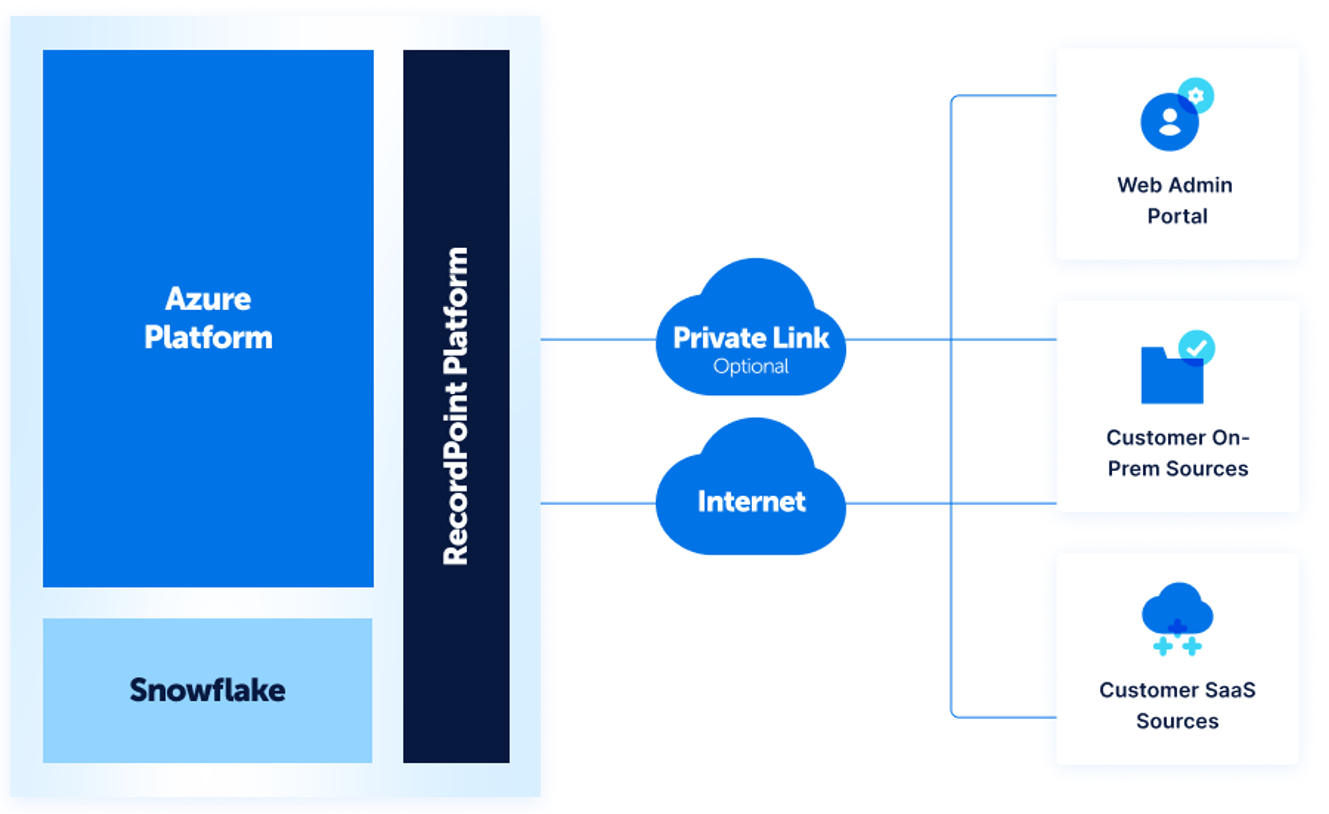
Architecture
he RecordPoint Platform consists of four major components:
- Intelligence pipeline
- Connector framework
- Search
- Secure storage
The Intelligent Policy engine sits at the heart of RecordPoint. It is responsible for processing ingested objects from content sources and categorizing items using a powerful rules engine. Only the metadata of an object is required to be ingested into RecordPoint. The file or document remains in place in the content source and can be edited by users in the content source.
The engine allows customers to create a unified set of rules for applying information governance policies across all connected content sources.
RecordPoint Connectors framework allows RecordPoint to easily manage content in multiple, heterogeneous content sources. A rich REST-based API surface allows content sources and types not natively supported to be rapidly integrated.
The Search component provides users with the ability to search through vast amounts of structured, semi-structured, and unstructured data that is being managed by RecordPoint.
RecordPoint federates with the customer’s MS Entra / Azure AD to provide a seamless single sign-on (SSO) experience for users needing to access the RecordPoint web portal. As a result, users can use their corporate credentials to sign in. In addition, any authentication policies, such as multi-factor authentication, are respected.
All service components are hosted on Microsoft Azure using a mix of virtualized compute resources and Platform as a Service (PaaS) offerings.
All service components are built to be fault tolerant with multiple levels of redundancy. Processing tasks carried out by the service are spread across a cluster of compute nodes. Compute clusters are resilient to single and multi-node failures. Furthermore, compute clusters can be rapidly scaled to provide additional throughput when processing demand peaks. Storage & backup components of the service are geographically redundant.
Cloud Locations
RecordPoint operates out of Microsoft Azure data centers in four major geographical regions: North America, Canada, Europe, and Asia Pacific. We operate our global operations center (GOC) out of Sydney, Australia, and Seattle, USA providing true global “follow the sun” capability.
Commercial Model
Overview
The RecordPoint Platform uses a plan-based reserved capacity pricing model.
The service is available on term contracts for an annual service fee based on the RecordPoint plan and add-ons chosen by the customer.
The RecordPoint plan and add-ons become fixed components of the minimum contracted service, determining the final annual price charged to a customer. Billing occurs annually in advance of the term of the agreement.
Additional add-ons or plan changes after the service is commissioned are billed in advance, pro-rated to the anniversary date of the service. Plan changes and / or additional add-ons become part of the new minimum contracted service that a customer is charged annually.
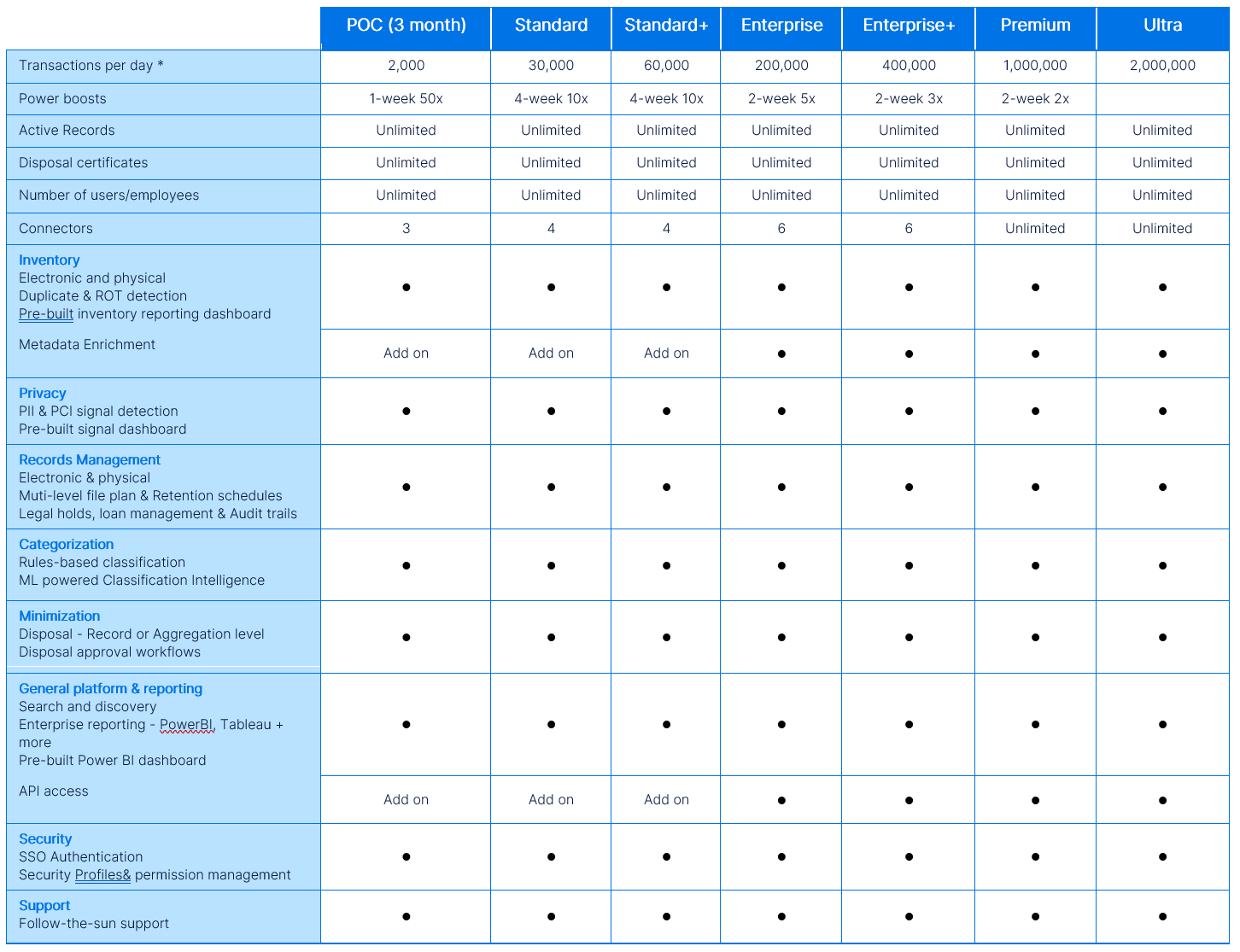
RecordPoint Platform Rate-Based Plans
Feature Add-ons
Additional connectors
The Connector framework allows for connection to hundreds of business systems. As most enterprise systems used today have characteristics unique to your organization, there may be additional costs for configuration.
File Analysis
Connect any unstructured file shares, such as SAMBA, Windows, Azure, AWS, etc. Assess for duplicates, ROT, PII, and PCI data. Data stays within your secure environment during the analysis.
Metadata Enrichment
Enriches the existing metadata by incorporating consistent and relevant additional information from external or third-party systems.
Classification Intelligence
Machine learning (ML)powered classification. Fully-integrated ML feature using text, Image, Optical Character Recognition (OCR). Train an ML model against thousands of categories.
Content-based search
Enables search functionality that examines the textual information within documents or data sets rather than just metadata.
Content Sampling
The Content Sampling feature efficiently handles binary ingestion by storing only essential binaries for a short duration. This enables ML model training without storing all binaries in RecordPoint, a requirement often sought by Financial Services customers.
Binary versions
An evergreen document with version history enables organizations to track and access all record versions, facilitating timely and accurate transfers and downloads for internal and external needs.
Infrastructure add-ons
Powerboost
A powerboost refers to a specific timeframe during which you can process records at an accelerated pace.
Multi Geo SPO
Allows for the management of customers who have multi-geo OneDrive and SharePoint Online infrastructure geographically separated.
Multi Tenancy
Allows for the management of customers who have multi-tenancy solutions, e.g. A single Active Directory and multiple RecordPoint Platform instances.
Remote Blob Storage
For organizations who want more control of their data, remote blob storage allows customers to use their own Azure storage to store binaries, rather than using RecordPoint’s secure storage facility.
API access
Integrate data with RecordPoint using our robust API (Application Programming Interface) allows you to extract and manipulate data, automate processes, and build custom integrations to meet your unique business needs.
IRAP
Allows customer to ensure that their environment remails IRAP certified.
Sentinel Log Shipping
Allows for the shipping of sentinel logs direct to customer.
Private Express Route
Guaranteed private link between RecordPoint and the customer's systems.
Consulting Services
Consulting services are considered extra and are charged at pre-agreed rates in addition to the service fee.
Invoicing
The annual service fee is billable in advance based on the minimum contracted service. Additional charges are invoiced on an annual prorated basis. Invoices are issued at the beginning of the month.
Renewals
RecordPoint will automatically generate renewal invoices 30 days in advance of term expiry.
Service Responsibilities
The table below outlines the high-level areas of RecordPoint responsibility and customer responsibility across the RecordPoint Platform service.
Customer responsibility
RecordPoint responsibility
Service Exclusions
The Service specifically excludes any item not explicitly described in this Service Description.
Prerequisites
Client Access
RecordPoint is designed to work with the following software:
- The current version of Edge and Chrome desktop browsers.
- The current version of Chrome for Android and IOS and Apple Safari on IOS.
All communication with the Service is conducted over a TLS connection to enhance security.
Although RecordPoint does not recommend that you connect to the RecordPoint Platform using older browsers and clients, we provide limited support as long as its manufacturer supports that software.
Specifically, if you continue to use older browsers and clients:
- RecordPoint won’t deliberately prevent you from connecting to the service.
- RecordPoint won’t provide code fixes to resolve problems related to those clients, but it will offer security fixes as needed.
- The quality of the user experience will diminish over time.
For the best experience using RecordPoint, we recommend always using the latest browsers, Microsoft Office clients, and apps. We also recommend that you install software updates when they become available.
MS Entra/Azured AD (Azure Active Directory)
RecordPoint leverages MS Entra / Azure AD to authenticate and authorize end-users as well as connect to remote content sources via the Connector framework. MS Entra / Azure AD is a prerequisite for usage of the service. MS Entra / Azure AD manages role assignments that provide end-users access to the RecordPoint portal through MS Entra / Azure AD.
Network Connection
The RecordPoint Platform is hosted entirely within Microsoft Azure and is available on the public Internet. One or more network connections to the public Internet will be required to connect a customer’s network to the Service. All communication with the service is conducted over a TLS-secured connection.
Service Levels
The RecordPoint Platform is available to customers 24 hours per day, 7 days per week, 365 days per year.
From time to time, the service may be impacted by maintenance windows. These windows will be communicated to customers via the change management process in advance and are not SLA-impacting.
Service Availability and Service Levels
The RecordPoint Platform is governed by a service level agreement (SLA) which is specific to you as a customer and forms part of your customer agreement.
The standard service availability, measured by Monthly Uptime Percentage for RecordPoint is 99.9%.
The method of calculation is shown below.
Downtime
Any period of time when the RecordPoint Platform is unavailable, and the service is not in a maintenance window. Unavailable is defined as an end-user being unable to connect to the RecordPoint portal (see service limitations for details).
No service levels are offered around ingestion latency from remote content sources. However, RecordPoint will endeavor to ensure that records are ingested continuously at a reasonable rate.
Monthly Uptime Percentage
The Monthly Uptime Percentage is calculated using the following formula:
(Service Minutes - Downtime Minutes) / (Service Minutes) x 100
Service Credits
Service Credits are your sole and exclusive remedy for any performance or availability issues for any Service under the Agreement and this SLA. You may not unilaterally offset your Applicable Monthly Service Fees for performance or availability issues.
Service Credits apply only to fees paid for the particular Service, Service Resource, or Service tier for which a Service Level has not been met. In cases where Service Levels apply to individual Service Resources or to separate Service tiers, Service Credits apply only to fees paid for the affected Service Resource or Service tier, as applicable. The Service Credits awarded in any billing month for a particular Service or Service Resource will not, under any circumstance, exceed your monthly service fees for that Service or Service Resource, as applicable, in the billing month.
If you purchased Services as part of a suite or other single offer, the Applicable Monthly Service Fees and Service Credit for each Service will be available for the least expensive element of the service as determined by us in our reasonable discretion.
Service Limitations
The standard Service Level Agreement and any applicable Service Levels do not apply to any performance or availability issues:
- Due to connectivity issues on the client premise or the premise from which an end-user is attempting to connect from
- Due to content sources outages (for example, SharePoint Online, Box or DropBox experience an outage)
- Due to misconfiguration or issues with the client’s MS Entra/Azure AD.
- Due to factors outside our reasonable control (for example, natural disaster, war, acts of terrorism, riots, government action, or a network or device failure external to our data centers, including at your site or between your site and our data center)
- Due to redundancy limitations in the base Azure platform, such as capacity and product availability issues that may arise during the partial or full outage of an Azure region.
- Caused by Microsoft in the base Azure Platform or by a third-party.
- That result from the use of services, hardware, or software not provided by us, including, but not limited to, issues resulting from inadequate bandwidth or related to third-party software or services.
- Caused by your use of a Service after we advised you to modify your use of the Service if you did not modify your use as advised.
- During or with respect to preview, pre-release, beta or trial versions of a Service, feature or software (as determined by us) or to purchases made using subscription credits.
- That result from your unauthorized action or lack of action when required, or from your employees, agents, contractors, or vendors, or anyone gaining access to our network by means of your passwords or equipment, or otherwise resulting from your failure to follow appropriate security practices.
- That result from your failure to adhere to any required configurations, use supported platforms, follow any policies for acceptable use, or your use of the Service in a manner inconsistent with the features and functionality of the Service (for example, attempts to perform operations that are not supported) or inconsistent with our published guidance.
- That result from faulty input, instructions, or arguments (for example, requests to access files that do not exist).
- That result from your attempts to perform operations that exceed prescribed quotas or that resulted from our throttling of suspected abusive behavior.
- Due to your use of Service features that are outside of associated Support Windows; or
- For licenses reserved, but not paid for, at the time of the Incident.
Binary Protection
The binary protection feature of RecordPoint is not intended to substitute, in any way, shape, or form, backups of the binaries (i.e., Word, Excel documents) in the content source(s) that are being managed by RecordPoint. The client is responsible for ensuring that appropriate backup & restore capabilities are in place to protect content in the managed content source(s). RecordPoint binary protection supports binaries up to 500 MB in size. Any binary that exceeds this limit will not be protected by RecordPoint.
Features in Preview
To obtain our customers’ early feedback and involve them in our Product development process, RecordPoint might make features available in a preview-only mode, which are explicitly excluded from any Service Levels defined in this Service Description.
Preview Features:
- Are not covered by our Standard Level Agreement;
- Are not covered by RecordPoint Support;
- May have limited or restricted functionality;
- May be available only in selected geographical regions.
Backup and Redundancy
Backup and Restore
RecordPoint has technical and operational controls in place to ensure that customer data is backed up in a secure and redundant manner.
All RecordPoint customer data is backed up at the following frequency:
- Full backups are taken once a week.
- Differential backups are taken twice a day.
- Transaction log backups are taken every 5 minutes.
Backups are stored in a geographically redundant manner, ensuring backups are available even in the event of a data center-level failure.
Backups are encrypted at rest using AES-256-bit encryption.
Backups are retained for up to 7 days.
These technical controls have been implemented to ensure that RecordPoint customers incur minimal data loss in the event of a disaster or service outage.
Service Continuity and Disaster Recovery
RecordPoint uses a variety of technical controls as well as a distributed service architecture to maximize service availability.
Using a distributed service architecture, RecordPoint is able to spread processing tasks across clusters of compute nodes, thereby eliminating service availability impacts of individual compute nodes failing.
In addition, the following technical controls are in place to maximize service availability:
- Service load balancing across compute clusters.
- Persistent message queuing to enable service components to pass durable messages to each other.
- Cloud-scale domain name systems (DNS).
- Segmentation of compute clusters into separate availability sets and update domains.
- Availability sets ensure that compute nodes within the same availability set are serviced by the same physical hosts, storage units, and network switches.
- Update domains ensure that updates are applied in a rolling fashion (one-by-one) across a single compute cluster.
- Storage redundancy to ensure that critical service data, such as customer data, is stored across multiple data centers.
RecordPoint tests service continuity and disaster recovery automation and procedures annually to ensure that these align with the RPO and RTO below.
Recovery Point Objective
The Recovery Point Objective (RPO) represents the maximum amount of time for which data loss may occur in the event of a service outage.
RecordPoint currently offers an RPO of twelve (12) hours for the RecordPoint Platform.
Recovery Time Objective
The Recovery Time Objective (RTO) represents the maximum time before the service becomes operational again after a service outage.
RecordPoint currently offers an RTO of forty-eight (48) hours for the RecordPoint Platform.
Limitations
The above RTO commitment is not applicable when the underlying base Azure platform is experiencing a complete outage in any of the Azure regions in which RecordPoint is hosted. In such scenarios, the RTO commitment only becomes effective once the impacted Azure region has recovered from the outage. The RecordPoint service has been designed to minimize data loss in the event of a service disruption by ensuring that connectors can track their progress of synchronizing changes from a connected content source in a durable way. This allows connectors to simply resume operation from where they left off prior to a service disruption.
Security and Risk Management
At RecordPoint, we understand that the security and privacy of your data are of utmost importance. As a trusted SaaS provider, we have implemented robust security measures to protect your data and ensure compliance with data protection regulations. RecordPoint has a rigorous set of technical and policy-based controls in place to ensure that customer data is kept secure and confidential.
The following controls are enforced by RecordPoint as part of the operation of the RecordPoint service:
Security Certifications
SOC2 Type 2
RecordPoint undergoes SOC 2 Type 2 audits to verify that technical and policy controls governing the security, availability and confidentiality of the RecordPoint Platform are operating correctly.
As part of the audit process, RecordPoint is assessed against the following trust service principles:
- Confidentiality – maintain all customer data as confidential.
- Security – protect the service against unauthorized access.
- Availability – maintain service availability for operation and use as committed or agreed.
A 3rd party auditor verifies that these controls and policies pertaining to the trust service principles are operating through a series of on-site interviews, control demonstrations and evidence-based analysis.
The latest SOC 2 Type 2 report can be made available upon request by emailing trust@recordpoint.com
IRAP Assessed to PROTECTED
RecordPoint has been assessed by an independent 3rd party assessor accredited under the Australian Federal Government’s IRAP Assessment Program.
The assessment includes a review of both the RecordPoint Platform and RecordPoint as an organization against the requirements of the Australian Government Information Security Manual (ISM) to store PROTECTED classified data.
The latest IRAP Assessment can be made available upon request by emailing trust@recordpoint.com
UK Cyber Essentials
RecordPoint has been certified against the UK National Cyber Security Centre’s Cyber Essentials standard. The latest Cyber Essentials certificate can be found using the NCSC Certificate search or by emailing trust@recordpoint.com
Service Updates
Maintenance Windows
Maintenance windows enable planned service interruptions so that essential maintenance, repairs, housekeeping or service upgrades can be carried out.
Such windows will be raised and notified through the change management process. Notification and approval will include, but not be confined to, the primary customer contact.
Service Updates
RecordPoint is an evergreen service, and service updates are regularly applied to the RecordPoint Platform. Service updates incur no downtime, and the RecordPoint Platform will remain available for the duration of the update being applied.
In special circumstances, RecordPoint may need to perform more complex service updates where the RecordPoint Platform becomes temporarily unavailable. In such cases, RecordPoint will schedule a maintenance window.
Service Monitoring and Management
The service provides a fully managed and supported records management service consisting of:
- The RecordPoint Platform includes a secure managed networking, compute, storage, and platform infrastructure.
- The RecordPoint support portal provides the ability to log and track service incidents, resolution of acknowledged service bugs and processing of enhancements, and access to RecordPoint online resources.
- The background IT service and system management systems that are used to provide issue, problem, incident, change and release management.
Systems Management
Various systems are in place to ensure that the systems underpinning RecordPoint are properly managed and monitored. These consist of:
- Help Desk System – System for clients to log support requests and work with RecordPoint support representatives:
- In our Australian data center, privileged accounts with access to sensitive data are only granted to Australian citizens.
- Application Monitoring Tools:
- Realtime monitoring of critical application and infrastructure metrics.
- Realtime alerting based of the metrics collected using the monitoring tooling.
- Historical reporting for trend and capacity analysis.
- Security Monitoring:
- Continuous vulnerability assessments for virtual hosts and virtual networks.
- Realtime monitoring of network traffic and security events for threat analysis and protection.
- Backup Tools – Capabilities such as virtual machine snapshotting and backup of critical storage components.
- Change Tracking System – Platform for raising, evaluating and tracking changes to production systems.
- Source Control System – Platform for engineers to submit and peer review enhancements and bug fixes to the various components that make up the service.
Service Monitoring and Capacity Management
The RecordPoint service is monitored 24 hours per day by our Site Reliability Engineering (SRE) team.
Applications, virtual hosts, networks, and storage are continuously monitored to ensure the service operates within desired service levels. Capacity is monitored to ensure that there are adequate compute, storage and networking resources to support the current service utilization plus any anticipated growth in utilization.
We also store anonymous data that allows us to track system trends, user activity, and the technical effects of onboarding new customers and new releases.
Anonymous age data is collected for capacity planning and monitoring purposes.
The following table shows indicative response times to proactively monitored events.
Support
RecordPoint provides support services to RecordPoint customers to ensure that any issues and questions encountered are resolved promptly.
RecordPoint offers a “follow-the-sun” support model in which support tickets are handled by and passed between support desks for increased responsiveness and around-the-clock support.
Upon commencement of the service, customers are onboarded to the RecordPoint support portal, which can be used to log support tickets (service requests) and access the RecordPoint knowledge base.
Support desks are situated in the locations listed below. Each support desk has its own dedicated phone number.
- Sydney, Australia.
- Seattle, United States.
RecordPoint will support the service in conjunction with the service levels defined in the customer agreement document.
Support Entitlements
The following tables describe the support entitlements included in each RecordPoint plan.
A RecordPoint support engineer will assess new service requests and adjust the priority, if necessary, in line with the priority levels described below.
Service Request Priorities
The following table describes how RecordPoint support assesses the priority of a new service request.
Service Request Logging
Service request logging is provided via web support portal, email and telephone.
The fastest method to get a response and a Support Engineer working on your problem is using the RecordPoint support portal. Regardless of whether service requests are logged by web, email or telephone, they are managed using the customer support portal and this will be the place where progress on support calls is reported and managed.
Onboarding and Offboarding
Service Activation
The RecordPoint service activation process consists of capturing information in the Service Data Sheet and various forms and documents that outline the service requirements, including production, staging and development service instances, site, and contact details.
- Information relevant to service activation includes items such as:
- Security requirements, including identity and access requirements.
- Number of records.
- Content sources to be managed.
- Estimated content size in TB by content source (if archiving).
- RecordPoint administrators.
- Customer contacts for the service.
Depending on the customer's needs, the RecordPoint offloading process service may incur additional costs charged on a cost recover basis.
The activation process then consists of the following:
- Appointment of an Onboarding Manager for the customer.
- Onboarding kick-off meeting.
- Provision of information.
- Service delivery enablement and acceptance.
Service Activation Pre-requisites
The following are pre-requisites to onboarding:
- Signed Customer Contract/Agreement.
- Customer purchase order.
- Approved Migration Plan.
The Migration Plan outlines the phasing of users onto the service, the major technical activities required, such as access planning, security requirements, and a plan for the initial submission of records into the RecordPoint service.
Additional Services
The following services are additional to the standard activation process and require additional scoping and investment.
- Migration Design and Implementation.
- Identity Federation.
- Other Advisory Services include network access plan, security assessment, migration readiness, etc.
- Other customer-specific onboarding activities.
Offboarding
The service off-boarding process consists of reviewing information in the Service Data Sheet, the various forms and documents that outline the customer’s provisioned services, including production, staging and development service instances, site and contact details.
The service deactivation process then consists of the following:
- Service deactivation according to the agreed plan.
- Furnishing of final backups to customer.
- Final invoicing.
- Customer satisfaction survey.
Encryption Statement
At RecordPoint, we are committed to upholding the strictest security on information that we retain and ensuring that your information remains protected when our solutions communicate with you or on your behalf.
We have made it our policy to encrypt and secure information that travels between our RecordPoint service and user computers, information that travels between the components of our systems that communicate over the internet and for critical data at rest.
This statement summarizes the use of encryption in the RecordPoint service and related RecordPoint computer and communications systems.
Information in Transit
Transport Layer Security (TLS) secures communication transmitted over the Internet using standard encryption technology. Securing communication this way reduces the risk of interception, eavesdropping, and forgery.
In RecordPoint, our TLS usage has the following attributes:
- RecordPoint uses TLS uniformly across all publicly available services – including our Azure-hosted web services.
- RecordPoint does not make use of transport layer security prior to TLS 1.2, such as SSL 3.0or other previous versions with well-known vulnerabilities.
- For internet communication, RecordPoint uses signing and encryption certificates issued by Public Certification Authorities using SHA-256 (SHA2) and a key length of 2048. Depending on the client a typical cipher negotiation would beAES256-SHA.
- TLS configuration and cipher strength is reviewed annually by a third-party auditor that verifies the correct TLS configuration (TLSv1.2 and above) as well as the removal of weak ciphers.
Information and Data Storage
RecordPoint applies encryption at the following layers:
Transparent Data Encryption is applied to our Azure SQL(Postgres) clusters and instances to ensure that data stored is secure. All data stored by the service is secured via the Azure Storage Service through 256bit AES encryption that is always on, cannot be turned off, and is FIPS 140-2compliant. Azure SQL for Postgres inherit network security and compliance from Microsoft Azure and provide a managed layered security model with DDoS protection, a secure gateway, SSL encrypted network traffic, native firewalls, native authentication, and finally all data is automatically encrypted by the service. This primarily protects against a scenario where the physical media(such as drives or backup tapes) are stolen and a malicious party is able to restore or attach the database and browse the data.
Backup Encryption is applied to all Azure SQL (Postgres) backups which are encrypted using AES 256-bit encryption. Backups are automatically managed by Azure.
Algorithms
Ciphers in use meet or exceed the set defined as “AES-compatible” or “partially AES-compatible” according to the IETF/IRTF Cipher Catalog or the set defined for use in the United States National Institute of Standards and Technology (NIST) publication FIPS 140-2, or any superseding documents according to the date of implementation.
Signature algorithm used is typically RSA with 2048 key length, PKCS#7.
Last updated: August 3, 2023